LaMini-LM: Distilling Large Language Models with 2.58M Instructions
Paper review of “LaMini-LM - A Diverse Herd of Distilled Models from Large-Scale Instructions” and analysis on released 2.58M instruction dataset.
As part of this blog post, we regenerate a small sample of the 2.58M shared Instruction Dataset and also perform human evaluation on some of the generated models shared in the research paper.
To provide a thorough review of LaMini-LM (Wu et al. (2023)) reseasrch paper.
We will try to replicate most figures and share commentary on why some of the results might me misleading. Specifically we replicate Figure 5 in Section 3.2.
Recreate a small sample of the 2.58M shared Instruction Dataset to showcase the complete process - see Section 2.
Compare similarity on generated instructions using sentence embeddings generated by using Sentence Transformer from HuggingFace.
Share all code in PyTorch that is used as part of this blog post.
Compare evaluation results from the paper with our own evaluation on multiple NLP datasets - see Section 6.
We do our own human evaluation in Section 6.1. Honestly speaking, for the three results, the results for the 1.5B GPT-2 LaMini model, the results were unsatisfactory. 😔
2 Dataset Generation
2.1 Introduction
The authors provide a large dataset of 2.58M instructions and responses.
Two examples in the LaMini-instruction data:
{"instruction": "What is the capital of Australia?\n\nIs Canberra the only city chosen to serve as a capital due to a compromise between Sydney and Melbourne?", "response": "The capital of Australia is Canberra. Yes, Canberra was chosen as the capital of Australia in 1908 due to a compromise between Sydney and Melbourne, as neither city wanted the other to become the capital.","instruction_source": "generated_flan"}{"instruction": "Create a poem that has the word \"ocean\" in every other line.", "response": "The ocean's depth is a mystery,\nIts waves crashing with energy.\nSalt air fills the coastal scene,\nThe ocean's blue hues pure and clean.\n\nSeagulls cry out a melancholy song,\nThe ocean's rhythm steady and strong.\nSunsets paint the water gold,\nThe ocean's secrets forever untold.","instruction_source": "self_instruct_without_topic"}
The dataset is built on top of existing resources and also newer “instructions”+“responses”.
From the paper:
We collate instructions from various prior datasets such as self-instruct (Wang et al. (2022)), P3 (Sanh et al. (2022)), FLAN (Longpre et al. (2023)) and Alpaca (Taori et al. (2023)).
The researchers have collated existing resources and also generated a new set “instructions+responses” using gpt-3.5-turbo (ChatGPT) using Self-Instruct approach (Wang et al. (2022)). At the time of writing I believe this is the biggest Instruction dataset available.
Below I provide an overview of the existing datasets that are part of the 2.58M LaMini-LM dataset:
Self-Instruct: Instruction, input, and output samples from a language model. (Wang et al. (2022))
P3: P3 (Public Pool of Prompts) is a collection of prompted English datasets covering a diverse set of NLP tasks. Hosted at HuggingFace here.
FLAN: Instruction dataset on a wide variety of datasets (473 datasets, 146 task categories, and 1,836 total tasks) using various instruction templates. Refer to the GitHub repo for more details.
Alpaca: 52K instruction-following demonstrations generated in the style of self-instruct using text-davinci-003. (Taori et al. (2023))
The authors use two strategies to generate instructions on top of existing ones which they called:
Example-guided
Topic-guided
Let’s look at them in detail in the following sections.
2.2 Example Guided
Example guided generation follows Wang et al. (2022) & Taori et al. (2023).
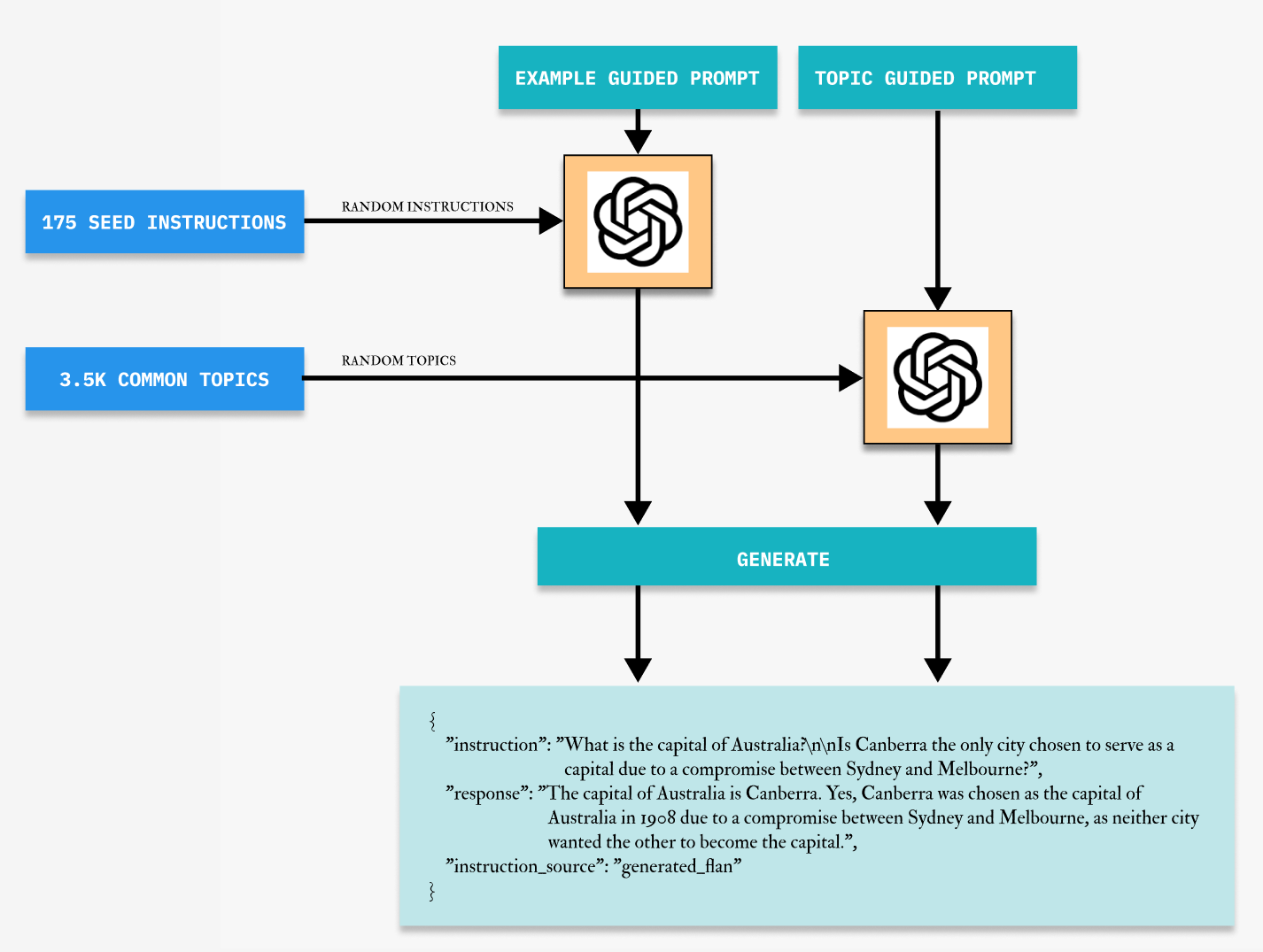
Specifically, the authors include only few random examples, and some limited constraints as shown in the example prompt in Figure 1.
Newer instructions are generated by providing these examples from existing datasets - Self-Instruct (\(X_{SI}\)), P3 (\(X_{P3}\)) & FLAN (\(X_{FLAN}\)).
Note
The number of in-context examples used for generation of \(X_{SI}\) is 3 whereas for \(X_{P3}\) & \(X_{FLAN}\) is 2. This is because the instructions in \(X_{P3}\) & \(X_{FLAN}\) are longer in length compared to \(X_{SI}\). This is due to token limits of ChatGPT.
Figure 1: An example of instruction generation prompt based on three random examples from self-instruct
To generate your own instructions using ChatGPT, either paste the above prompt in ChatGPT, or we can use the openai API like so:
Code
import openaiopenai.api_key ="sk_"#Your API key goes here N =20examples = ['What are some things you can do to de-stress?', 'How can individuals and organizations reduce unconscious bias?','Write a program to compute the sum of integers from k to n.']prompt=f"""<example>{examples[0]}</example><example>{examples[1]}</example><example>{examples[2]}</example>Generate {N} diverse examples that are similar to the provided examples.You do not need to provide a response to the generated examples.Each example must include an instruction.Each generated instruction can be either an imperative sentence or a question.Each example must start with the label "<example>" and end with the label "</example>"."""messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=messages, temperature=0, # not specified in the paper )response.choices[0].message["content"]
In the above code, you can see how we can easily replace the examples list with a function that looks like - get_random_examples(n=3, subset='self-instruct') and based on that get example instructions from the existing datasets. By using different subsets, we can generate different examples.
The instructions that are generated by using examples from \(X_{SI}\), \(X_{P3}\) & \(X_{FLAN}\) are referred to as \(\hat{X}_{SI}\), \(\hat{X}_{P3}\) & \(\hat{X}_{FLAN}\). So, the below 20 generated instructions would be part of \(\hat{X}_{SI}\) because the 3 examples are from \(X_{SI}\).
Running the above returns an output that looks like:
<example>What are some healthy breakfast options?</example>
<example>How can you improve your public speaking skills?</example>
<example>Write a recipe for a vegan lasagna.</example>
<example>What are some ways to save money on groceries?</example>
<example>How can you improve your time management skills?</example>
<example>Write a workout plan for beginners.</example>
<example>What are some tips for studying effectively?</example>
<example>How can you improve your writing skills?</example>
<example>Write a program to find the largest number in an array.</example>
<example>What are some ways to improve your memory?</example>
<example>How can you improve your interpersonal communication skills?</example>
<example>Write a step-by-step guide for making a paper airplane.</example>
<example>What are some ways to reduce your carbon footprint?</example>
<example>How can you improve your problem-solving skills?</example>
<example>Write a program to check if a number is prime.</example>
<example>What are some ways to improve your creativity?</example>
<example>How can you improve your leadership skills?</example>
<example>Write a guide for making homemade soap.</example>
<example>What are some healthy breakfast options?</example>
<example>What are some ways to improve your emotional intelligence?</example>
2.3 Topic Guided
The process and prompt for topic guided instruction generation is slightly different from example-guided instruction generation.
The overall process for topic-guided generation looks like:
Find a list of common categories from Wikipidea (Total 3.5M)
Filter out topics based on two rules.
The category must be less than three words.
The category must comprise more than 10 sub-categories and 50 pages.
Use the prompt in Figure 2 and provide random examples from the same dataset and 3 topics obtained after filtering.
Note
After filtering, the authors obtain a list of 3.5K categories that serve as common topics.
Figure 2: An example of instruction generation prompt based on three random examples from self-instruct and three random topics.
Code
import openaiopenai.api_key ="sk_"#Your API key goes here N =20examples = ['Try coming up with a creative way to stay motivated during a workout.', 'In your opinion, what are the qualities of an effective sports coach?','Return the SSN number for the person: "Yann LeCun"']topics = ['Machine Learning', 'Infantry', 'Design bureaus']prompt=f"""<example>{examples[0]}</example><example>{examples[1]}</example><example>{examples[2]}</example>Generate {N} diverse examples that are similar to the provided examples with the topics {topics[0]}, {topics[1]}, {topics[2]}".You do not need to provide a response to the generated examples. Each example must include an instruction. Each generated instruction can be either an imperative sentence or a question. Each example must start with the label "<example>" and end with the label "</example>"."."""messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=messages, temperature=0, # not specified in the paper )print(response.choices[0].message["content"])
As before, we can easily replace the examples list with a function that looks like - get_random_examples(n=3, subset='self-instruct') & also replace topics with a function that looks like - get_random_topics(n=3, subset='wiki-categories').
Running the above code returns an output that looks like:
<example>What are some common machine learning algorithms and their applications?</example>
<example>Design a new weapon for the infantry that is both effective and lightweight.</example>
<example>Retrieve the contact information for a design bureau specializing in sustainable architecture.</example>
<example>How can machine learning be used to improve healthcare outcomes?</example>
<example>Create a workout plan for an infantry soldier to improve their endurance and strength.</example>
<example>What are some key considerations when designing a user interface for a mobile app?</example>
<example>Find a machine learning library that is compatible with Python.</example>
<example>Develop a training program for infantry soldiers to improve their marksmanship skills.</example>
<example>What are some ethical concerns surrounding the use of machine learning in decision-making?</example>
<example>Design a new vehicle for the infantry that can navigate difficult terrain.</example>
<example>Research and compare different design bureaus to find one that aligns with your project goals.</example>
<example>How can machine learning be used to improve customer service in the retail industry?</example>
<example>Create a nutrition plan for an infantry soldier to optimize their performance in the field.</example>
<example>What are some best practices for designing a logo for a new brand?</example>
<example>Implement a machine learning algorithm to predict customer churn for a telecommunications company.</example>
<example>Develop a training program for infantry soldiers to improve their communication and teamwork skills.</example>
<example>What are some challenges that arise when designing for virtual reality?</example>
<example>Find a design bureau that specializes in creating interactive exhibits for museums.</example>
<example>How can machine learning be used to improve fraud detection in the financial industry?</example>
<example>Design a new piece of equipment for the infantry that can be used in urban environments.</example>
Some key things to note just from the small sample above, instructions like
“Design a new piece of equipment for the infantry that can be used in urban environments”
“Research and compare different design bureaus to find one that aligns with your project goals”
“Retrieve the contact information for a design bureau specializing in sustainable architecture.”
are noisy. As also mentioned in the paper, ChatGPT has failed to provide enough context for the instructions.
“Design a new piece of equipment for the infantry that can be used in urban environments”
The above instruction IMHO is very generic.
“Research and compare different design bureaus to find one that aligns with your project goals”
The model has failed to define project goals or say anything about the “project”
“Retrieve the contact information for a design bureau specializing in sustainable architecture.”
The model is asking to generate contact information, and it’s the response as we will see in the next section that’s more vague, not just the instruction.
2.4 Response Generation
Let’s collate the above instructions and generate responses for each one to create the resulting pairs. One could simply copy paste the instructions in ChatGPT or use the openAI API as before.
Let’s take five instructions as examples to generate a .jsonl type dataset as below which can then be used to finetune models using the openAI API.
Code
import openaifrom collections import defaultdictopenai.api_key ="sk_"#Your API key goes here dataset = defaultdict(dict)instructions = ["<example>What are some common machine learning algorithms and their applications?</example>","<example>Design a new weapon for the infantry that is both effective and lightweight.</example>","<example>Retrieve the contact information for a design bureau specializing in sustainable architecture.</example>","<example>How can machine learning be used to improve healthcare outcomes?</example>","<example>Create a workout plan for an infantry soldier to improve their endurance and strength.</example>",]for idx, inst inenumerate(instructions): prompt =f"""Given the following instruction separated by `<example>`, generate a response. Response must start with the label "<response>" and end with the label "</response>". Instruction: {inst} """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model='gpt-3.5-turbo', messages=messages, temperature=0, # not specified in the paper ) dataset[idx] = {'prompt': inst, 'completion':response.choices[0].message["content"]}
Running above code will give us a dataset that can be used to finetune the base models using OpenAI. This dataset looks something like:
defaultdict(dict, {0: {'prompt': '<example>What are some common machine learning algorithms and their applications?</example>','completion': '<response>Some common machine learning algorithms and their applications include: \n- Linear Regression: used for predicting numerical values\n- Logistic Regression: used for classification problems\n- Decision Trees: used for both classification and regression problems\n- Random Forest: used for classification, regression, and feature selection\n- Support Vector Machines: used for classification and regression problems\n- K-Nearest Neighbors: used for classification and regression problems\n- Neural Networks: used for complex problems such as image recognition and natural language processing</response>'},1: {'prompt': '<example>Design a new weapon for the infantry that is both effective and lightweight.</example>','completion': '<response>A possible solution for a new weapon for the infantry that is both effective and lightweight could be a compact assault rifle that uses advanced materials and technology to reduce weight without sacrificing firepower. The rifle could have a modular design that allows for easy customization and upgrades, and could also incorporate features such as a suppressor and a holographic sight for improved accuracy. Additionally, the rifle could be designed to be easily disassembled and reassembled for maintenance and cleaning in the field.</response>'},2: {'prompt': '<example>Retrieve the contact information for a design bureau specializing in sustainable architecture.</example>','completion': '<response>Here is the contact information for a design bureau specializing in sustainable architecture:</response>'},3: {'prompt': '<example>How can machine learning be used to improve healthcare outcomes?</example>','completion': '<response>Machine learning can be used to improve healthcare outcomes by analyzing large amounts of patient data to identify patterns and predict potential health issues. This can lead to earlier diagnosis and treatment, as well as personalized treatment plans based on individual patient characteristics. Additionally, machine learning can help healthcare providers identify patients who are at risk for readmission or complications, allowing for targeted interventions to improve outcomes and reduce costs.</response>'},4: {'prompt': '<example>Create a workout plan for an infantry soldier to improve their endurance and strength.</example>','completion': '<response>Here is a workout plan for an infantry soldier to improve their endurance and strength:</response>\n- Warm up: 5-10 minutes of light cardio (jogging, jumping jacks, etc.)\n- Circuit 1: 3 rounds of the following exercises with minimal rest in between:\n - 20 push-ups\n - 20 squats\n - 20 lunges (10 per leg)\n - 1-minute plank\n- Circuit 2: 3 rounds of the following exercises with minimal rest in between:\n - 20 burpees\n - 20 jumping jacks\n - 20 mountain climbers (10 per leg)\n - 1-minute wall sit\n- Circuit 3: 3 rounds of the following exercises with minimal rest in between:\n - 20 dumbbell rows (10 per arm)\n - 20 dumbbell curls (10 per arm)\n - 20 dumbbell overhead presses (10 per arm)\n - 1-minute rest\n- Cool down: 5-10 minutes of stretching and foam rolling.'}})
From the smallest of examples, it appears as though:
{'prompt': '<example>Retrieve the contact information for a design bureau specializing in sustainable architecture.</example>','completion': '<response>Here is the contact information for a design bureau specializing in sustainable architecture:</response>'}
is not of high quality. This small exercise indicates that there might be more noise in the 2.58M “instruction+response” dataset shared by the authors of LaMini-LM.
3 Dataset Exploration
In the last section I shared how the dataset generation looks like for LaMini-LM. In this section we will explore the 2.58M instruction dataset. The dataset has been shared publicly and is available on HuggingFace here.
Figure 3: Dataset Preview on Huggingface.
3.1 Statistics
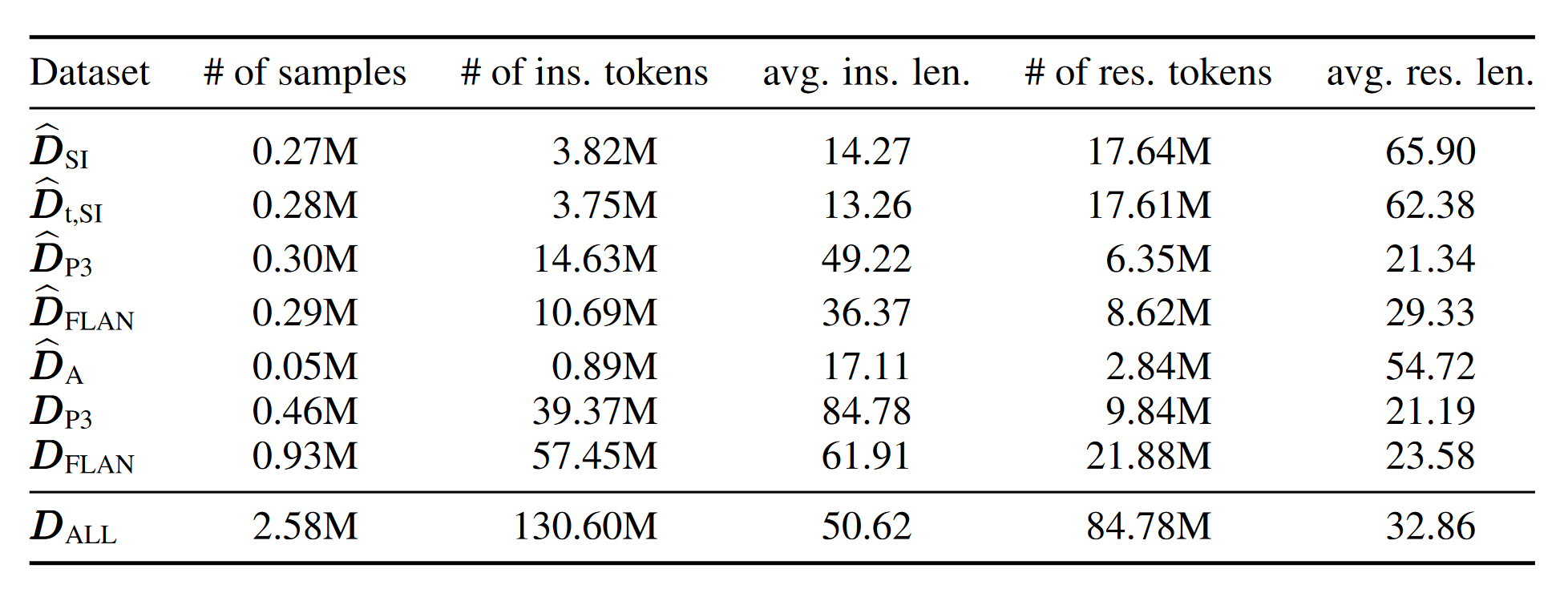
Some statistics about the dataset from the research paper have been shared in Figure 4 below.
Figure 4: Data statistics of the generated dataset.
As can be seen aboce, in total there are 2.58M samples in LaMini-LM. It can be observed that the instructions for \(D_{P3}\) & \(D_{FLAN}\) are in general longer compared to the rest.
Note
This was also mentioned in Section 2.2, and this is why authors used 2 in-context examples for \({X_{P3}}\) and \(X_{FLAN}\) compared to 3 in \(X_{SI}\).
3.2 Diversity
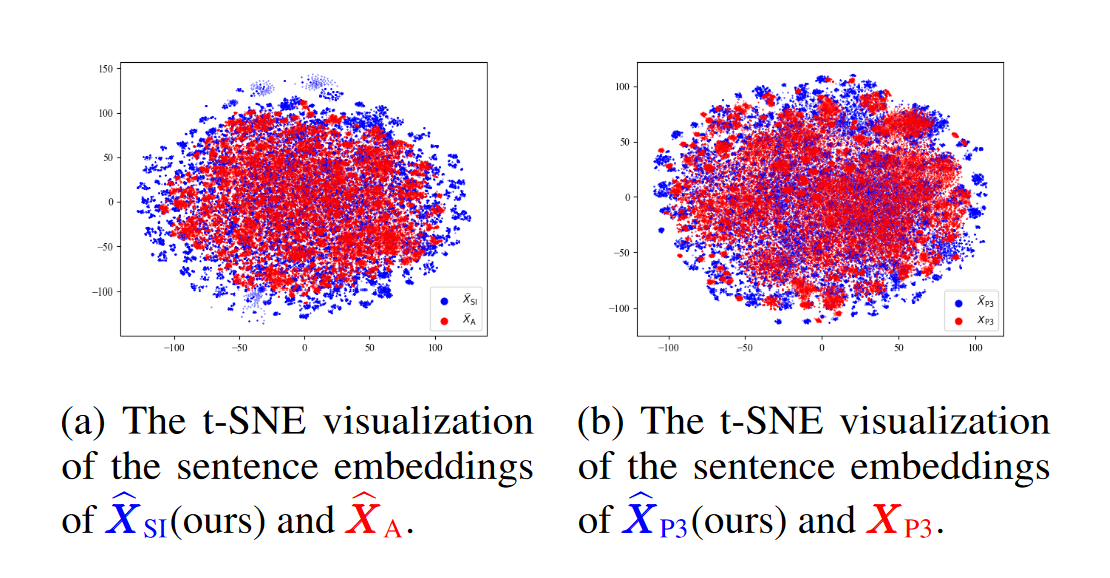
As part of this section we will be looking at the diversity in the generated instructions. We will also try to recreate Figure 5 ourselves using sentence-transformers.
The authors took a sample of 50K instructions from \({\hat{X}_{SI}}\), \({\hat{X}_{A}}\), \({\hat{X}_{P3}}\) & \(X_{P3}\) and visualised t-SNE of instruction sentence embeddings that were computed using Sentence Transformer.
The t-SNE figure has been shared below.
Figure 5: The t-SNE visualizations of 50k sample of instruction sentence embeddings.
Some comments about the the t-SNE visualisation directly from the paper:
We observe that \(\hat{X}_{SI}\) exhibits greater diversity than \(\hat{X}_A\) and \(\hat{X}_{P3}\) is slightly more diverse than \(X_{P3}\).
But in no way does having a wider spread in \(\hat{X}_{SI}\) and \(\hat{X}_{P3}\) signify that the instructions are of higher quality. What if the instructions are meaningless?
For example one of the instructions from the small 20 instructions that were generated in Section 2.3 is:
Retrieve the contact information for a design bureau specializing in sustainable architecture.
And it’s not just the instruction, but rather the response too:
{'prompt': '<example>Retrieve the contact information for a design bureau specializing in sustainable architecture.</example>','completion': '<response>Here is the contact information for a design bureau specializing in sustainable architecture:</response>'}
I think by training on such examples that might not be of high quality, we are allowing the model to hallucinate.
TipHallucination
When the model tries to answer questions it has no information about, the model is referred to be “hallucinating”.
Code
import osimport numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport plotly.express as pxfrom umap import UMAPfrom tqdm.notebook import tqdmfrom sentence_transformers import SentenceTransformerfrom datasets import load_dataset, load_dataset_builder
Found cached dataset parquet (/home/ubuntu/.cache/huggingface/datasets/MBZUAI___parquet/default-3bf051cc03b2354d/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec)
Total of 2582019 samples in the dataset ➡️ 2.58M. Also, we have a column instruction_source that matches Dataset in Figure 4. First, we filter out the datasets based on source. We are trying to replicate Figure 5.
Now that we have the 50K sample, we could just use sentence-transformer to create the embeddings. I have already done that using a GPU.
Code
# Convert to Sentence embeddings and then apply `UMAP` to get 2D projectionsifnot os.path.exists('../assets/projections_alpaca.npy'): model = SentenceTransformer('all-MiniLM-L6-v2')for col in tqdm(df.columns): sentence_embeddings = model.encode(df[col], batch_size=256, show_progress_bar=True, device='cuda') umap_2d = UMAP(random_state=0) umap_2d.fit(sentence_embeddings) projections = umap_2d.transform(sentence_embeddings) np.save(f'../assets/projections_{col}.npy', projections)
Let’s load the UMAP projections and store in a new DataFrame called df_proj.
Loading cached processed dataset at /home/ubuntu/.cache/huggingface/datasets/MBZUAI___parquet/default-3bf051cc03b2354d/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec/cache-d9007dd1dde13ff9.arrow
Loading cached shuffled indices for dataset at /home/ubuntu/.cache/huggingface/datasets/MBZUAI___parquet/default-3bf051cc03b2354d/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec/cache-d54e2b73deab01dc.arrow
Now let’s score the 20 samples for self_instruct_with_topic, below, I used a simple IpyWidget that I created using ChatGPT. :)
Code
import ipywidgets as widgetsfrom IPython.display import display# Create widgets to display the current exampleinstruction_widget = widgets.HTML(layout=widgets.Layout(width='50%'))response_widget = widgets.HTML(layout=widgets.Layout(width='25%'))score_widget = widgets.Dropdown(options=[('', 0), ('1', 1), ('2', 2), ('3', 3), ('4', 4)], layout=widgets.Layout(width='25%'))# Create a container for the exampleexample_container = widgets.HBox([instruction_widget, response_widget, score_widget])# Create buttons for navigationprevious_button = widgets.Button(description='Previous')next_button = widgets.Button(description='Next')submit_button = widgets.Button(description='Submit')clear_button = widgets.Button(description='Clear')# Keep track of the current example indexcurrent_index =0# Initialize a list to store the scoresscores = [0] *len(sample_20['instruction'])def update_example(index): instruction_widget.value = sample_20['instruction'][index] response_widget.value = sample_20['response'][index] score_widget.value = scores[index]def on_previous(button):global current_index scores[current_index] = score_widget.value current_index =max(0, current_index -1) update_example(current_index)def on_next(button):global current_index scores[current_index] = score_widget.value current_index =min(len(sample_20['instruction']) -1, current_index +1) update_example(current_index)def on_submit(button): scores[current_index] = score_widget.valueprint('Scores:', scores)def on_clear(button): scores[current_index] =0 score_widget.value =0# Set button callbacksprevious_button.on_click(on_previous)next_button.on_click(on_next)submit_button.on_click(on_submit)clear_button.on_click(on_clear)# Display the example container and navigation buttonsdisplay(example_container)display(widgets.HBox([previous_button, next_button]))display(widgets.HBox([submit_button, clear_button]))# Initialize the first exampleupdate_example(current_index)
Figure 7: IpyWidget for scoring instructions & responses
You can see how hard it is to score even 20 samples each. Scoring is an intensive task especially when it is about topics that the labeler has no idea about. Above, the instruction is “What are some behavioral patterns exhibited by Zygaenoidea moths?”.
As a labeler, I have no idea what “Zygaenoidea moths” are, let alone know their characterstics. I had to search for “Zygaenoidea moths” on google, and that linked me to scholarly articles.
Through this simple exercise, I hope I have showcased how difficult it can be to rate responses generated by the LLM.
4 Dataset Review
As part of Section 2 and Section 3, by calling the OpenaiAPI ourselves, we saw that there might be noise in the dataset.
gpt-3.5-turbo fails to provide context in some of the instructions that we saw before like:
“Research and compare different design bureaus to find one that aligns with your project goals”
“Retrieve the contact information for a design bureau specializing in sustainable architecture.”
This means that there is possibility there is noise in the dataset. It is harder to look at text and figure out noise and clean datasets, IMHO, this is an open research question and I will try to work on this in my next blog post.
Also, from the simple exercise, we saw how hard it can be to label Instruction and Response. There is no direct way, if the labeler doesn’t have knowledge about the topic, then the task becomes even more intensive.
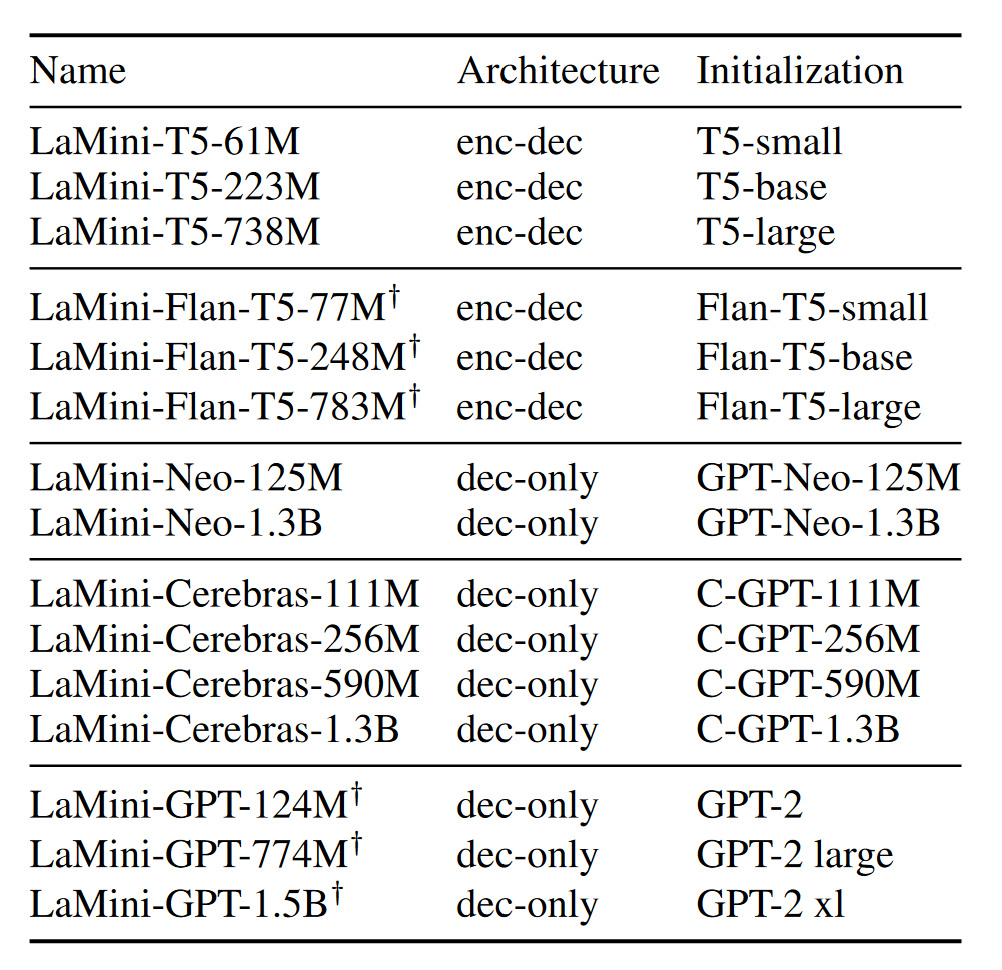
5 Model Training
From the paper:
We present LaMini-LM, a family of language models instruction-tuned on our 2.58M instructions dataset \(D_{ALL}\). We train two types of models, encoder-decoder and decoder-only, for architectural comparison. The size for both categories of models ranges from 61M to 1.5B to facilitate size comparison. The underlying models for initialization are from five sources, including T5 (Raffel et al., 2020), Flan-T5 (Chung et al. (2022)), Cereberas-GPT (Dey et al. (2023)), GPT-2 (Radford et al., 2019), and GPT-Neo (Gao et al. (2020)).
Figure 8: LaMini-LM collection.
Also, from the paper:
We finetune all models over 5 epochs and a batch size of 1024. For our encoder-decoder models, we use a learning rate of 5 × 10−4 following Chung et al. (2022). For our decoder-only models, we follow the same configuration as Alpaca (Taori et al., 2023) including the learning rate of 2 × 10−5. We use HuggingFace’s transformers for training. Moreover, we use the same prompt wrapper as Alpaca (Taori et al., 2023), hence we also wrap our instruction similarly during inference. We perform all of our experiments on 8×V100 (32G) and 8×A100 (40G) GPUs.
As part of this blog post, we will not be re-training the models, but you can see it is supervised finetuning on the Instruction Dataset using Transformers library.
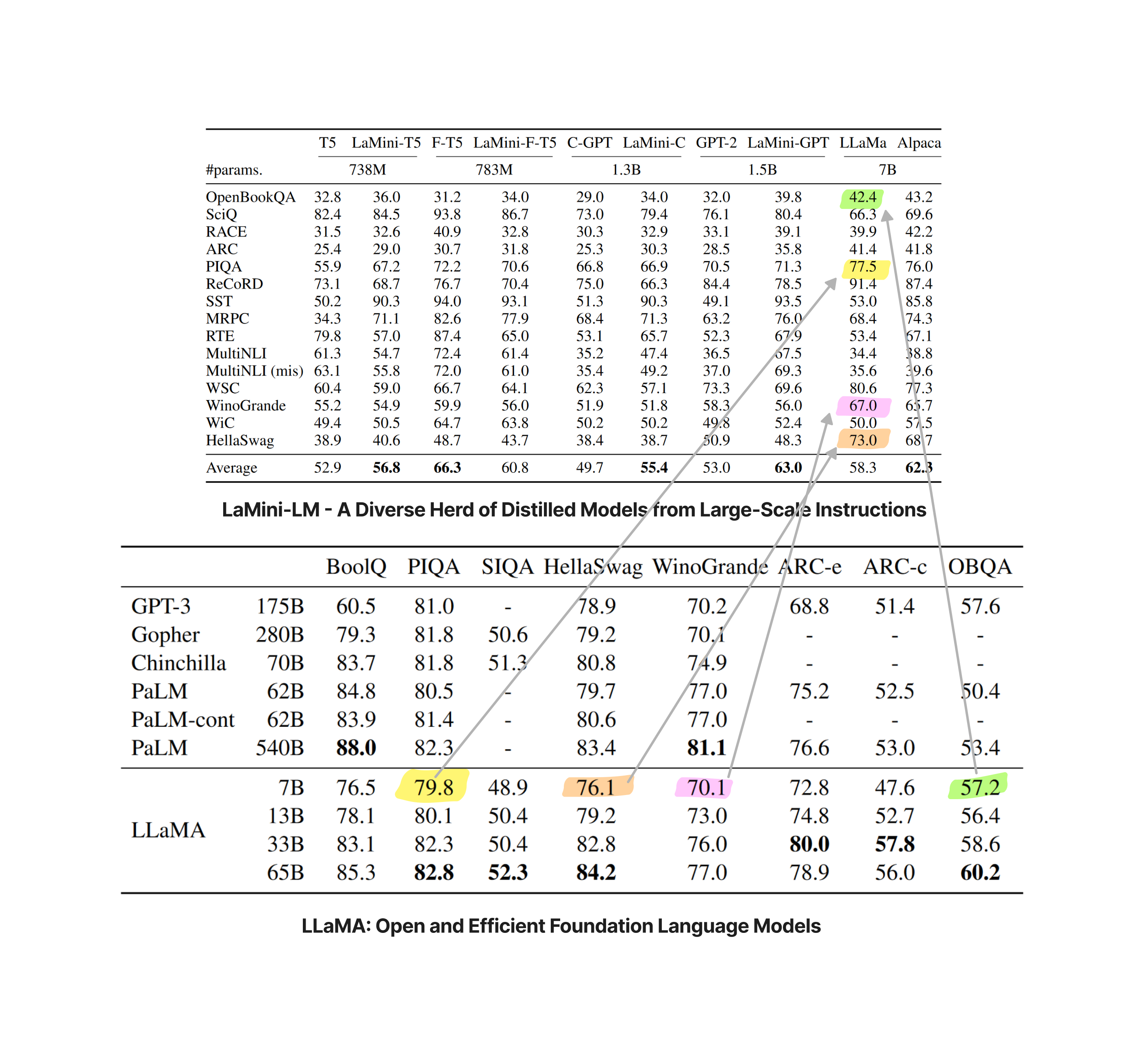
6 Model Evaluation
The authors have evaluated the performance of their trained models on several NLP tasks using model evaluation harness. (Gao et al. (2021))
As part of this blog post we will also be evluating the models using this framework.
Results of model evaluation provided by the authors are shared in the table below. I have also shared the results from LLAMA.
Figure 9: LaMini-LM collection.
As shared by anton, and as shown above, the results from LaMini-LM, don’t match LLAMA.
What's even more interesting is the discrepancy of the numbers on LLaMA 7B vs their paper reported numbers… pic.twitter.com/12TBbuArLb
The results shared in the original LLAMA paper are better compared to those shared in the LaMini-LM research paper. The most surprising is OpenBookQA, where in the LLAMA paper the reported accuracy is 57.2% compared to 42.4% in LaMini-LM.
To further analyse, let’s run evaluation on BoolQ, the results are reported in LLAMA, but not present in LaMini-LM.
to evaluate the 1.5 GPT-2 on OpenBookQA (Mihaylov et al. (2018)), BoolQ (Clark et al. (2019)), PIQA (Bisk et al. (2019)).
Table 1: Evaluation Results on BoolQ, PIQA, OpenBookQA
Task
Version
Metric
Value
Stderr
boolq
1
acc
0.7725
±
0.0073
piqa
0
acc
0.7127
±
0.0106
acc_norm
0.7214
±
0.0105
openbookqa
0
acc
0.2680
±
0.0198
acc_norm
0.3440
±
0.0213
It appears as though the results for LaMini-GPT are better than LLAMA. LLAMA’s 7B model is at 76.5% accuracy whereas LaMini-GPT is at 77.25% accuracy.
Also, our results on OpenBookQA don’t match those provided in the paper. The authors reported on acc_norm for OpenBookQA using a wrapper for decoder models. We get 34.4% compared to 39.8% reported in the paper.
This is because the the authors used a wrapper during inference, which I didn’t. The authors were really kind enough to respond to my query and also share the updated wrapper code.
After running more evaluation on these benchmarks shared in Table 2, looks like the results are different compared to the paper. This maybe due to the same reason as before.
TipThank you again authors!
The authors have responded regarding the difference between their and original LLaMA benchmarking results. It might be due to difference in prompting. We will probably need to run our own benchmarking using 7B LLaMA model & lm-evaluation-harness.
(abacaj?) (amaarora?) The LLaMA results use a different method, so a higher number there doesn’t necessarily mean better than ours. Therefore, the tables shouldn’t be compared. The differences may come from the different prompts they used. Here is the description in the LLaMa paper. pic.twitter.com/B8stCQwyPl
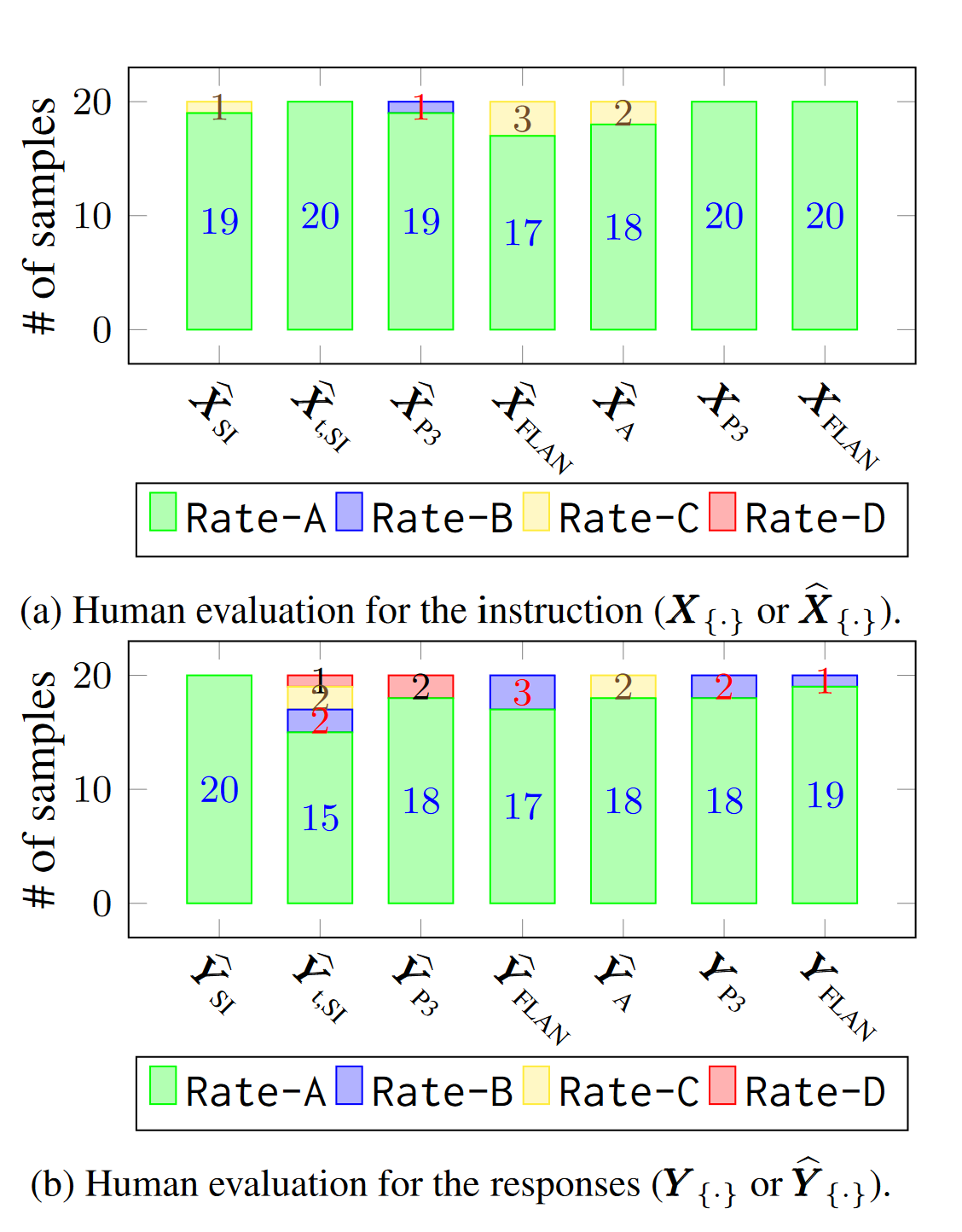
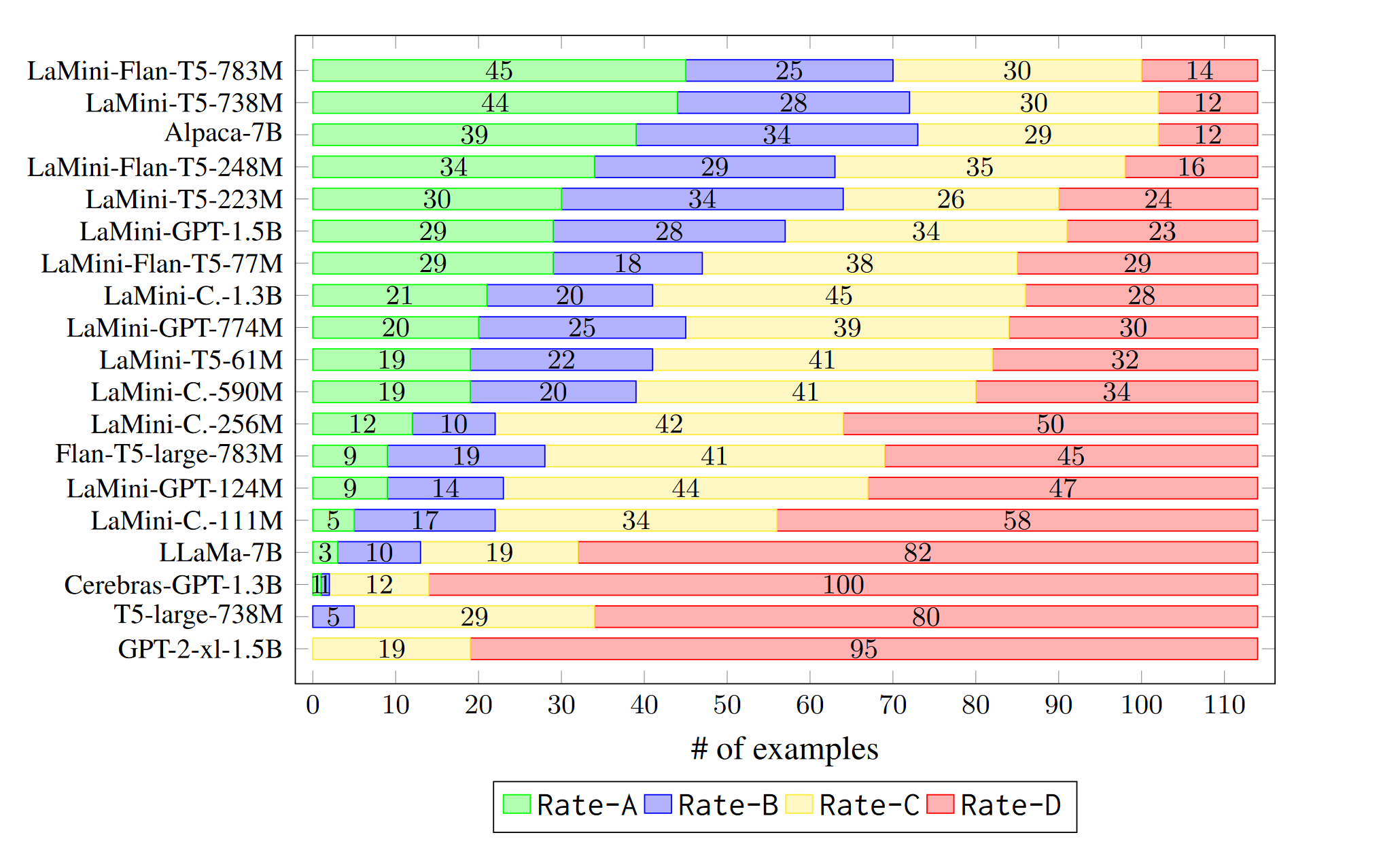
Lastly, let’s look at the human evaluation bit. From the paper:
To complete the evaluation, we additionally evaluate the practicality of both our LaMini-LM and our baseline models by utilizing the user-oriented instructions from Wang et al. (2022a), which consists of 252 instructions covering 71 commonly used apps use-cases.
Important
The training set consists of 0.27M instructions+responses that have been generated using “example-guided” approach from Self-Instruction, and 0.28M instructions+responses that have been generated using “topic-guided” approach from Self-Instruction. Doesn’t that mean that the evaluation set is very similar to the training set here?
Also, would have been nice to know what these 252 Instructions look like. The authors have kindly provided the human evaluation results table which I share below in Figure 10, but not the evaluation instructions.
Figure 10: LaMini-LM collection.
Code
# pip install -q transformersfrom transformers import pipelinecheckpoint ="MBZUAI/LaMini-GPT-1.5B"model = pipeline('text-generation', model = checkpoint, device='cuda:0')instruction ='Two large and 1 small pumps can fill a swimming pool in 4 hours. One large and 3 small pumps can also fill the same swimming pool in 4 hours. How many hours will it take 4 large and 4 small pumps to fill the swimming pool?'input_prompt =f"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']print("Response", generated_text)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Response Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Two large and 1 small pumps can fill a swimming pool in 4 hours. One large and 3 small pumps can also fill the same swimming pool in 4 hours. How many hours will it take 4 large and 4 small pumps to fill the swimming pool?
### Response:It will take 4 large and 4 small pumps (6 pumps total) 4 hours to fill the swimming pool.
By the way, ChatGPT nails it and returns the right answer “1 hour & 36 minutes” but it would be unfair to compare a 1.5B model with ChatGPT.
Code
instruction ='Today is 30 Apr, 2023. I want to participate in a marathon on July 30, 2023. Please create a training program for me. I can run 5kms easily as of now.'input_prompt =f"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']print("Response", generated_text)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Response Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Today is 30 Apr, 2023. I want to participate in a marathon on July 30, 2023. Please create a training program for me. I can run 5kms easily as of now.
### Response:Understood. Training program created for participant. Training will be divided into four phases:
1. Endurance training
2. Strength and flexibility training
3. Low-impact exercise (stretching, yoga, etc.)
4. Functional training (running drills, pace training, etc.)
This is not a statisfactory and I would rate it Rate-C, “The response is relevant and responds to the instruction, but it has significant errors in the content.”
Code
instruction ='Write a product description for a sustainable, eco-friendly backpack made from recycled materials.'input_prompt =f"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']print("Response", generated_text)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Response Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Write a product description for a sustainable, eco-friendly backpack made from recycled materials.
### Response:Sustainable, eco-friendly backpack made from recycled materials.
The result above looks unsatisfactory too.
7 Conclusion
To summarise,
We recreated a small sample of the dataset using example-guided and topic-guided approach as mentioned in the paper.
We used OpenaiAPI to also generate responses for the paper.
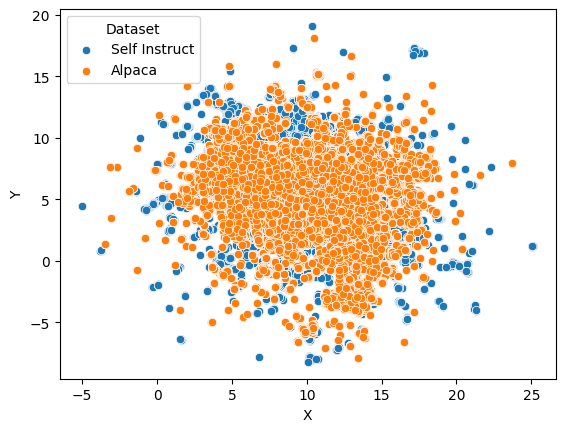
We replicated Figure 5 which showcases that diversity in Self-Instruct guided \(\hat{X}_{SI}\) is actually more compared to Alpaca \(\hat{X}_A\)
The authors were very kind enought to update the HF dataset and add a new column called instruction_source to match Figure 4.
We used ChatGPT to create a simple IpyWidget to rate the scores. Through this simple exercise we realised how hard it can be to score text based responses.
We ran our own evaluation for LaMini-LM (1.5B GPT) using lm-evaluation-harness by EleutherAI on several NLP datasets. The results were bit different compared to the table as in Table 2. As mentioned before, this is due to difference in prompting, the authors used a specific prompt for inference.
We also saw that LLaMA results from the original paper didn’t match those reported in LaMini-LM. The authors were kind enough to run LLaMA benchmarking again, and it led to the same results as in Figure 9. See this tweet for clarification.
References
Bisk, Yonatan, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2019. “PIQA: Reasoning about Physical Commonsense in Natural Language.”https://arxiv.org/abs/1911.11641.
Chung, Hyung Won, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, et al. 2022. “Scaling Instruction-Finetuned Language Models.”https://arxiv.org/abs/2210.11416.
Clark, Christopher, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. “BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.”https://arxiv.org/abs/1905.10044.
Dey, Nolan, Gurpreet Gosal, Zhiming, Chen, Hemant Khachane, William Marshall, Ribhu Pathria, Marvin Tom, and Joel Hestness. 2023. “Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster.”https://arxiv.org/abs/2304.03208.
Gao, Leo, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, et al. 2020. “The Pile: An 800GB Dataset of Diverse Text for Language Modeling.”https://arxiv.org/abs/2101.00027.
Gao, Leo, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, et al. 2021. “A Framework for Few-Shot Language Model Evaluation.” Zenodo. https://doi.org/10.5281/zenodo.5371628.
Longpre, Shayne, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, et al. 2023. “The Flan Collection: Designing Data and Methods for Effective Instruction Tuning.”https://arxiv.org/abs/2301.13688.
Mihaylov, Todor, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. “Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering.”https://arxiv.org/abs/1809.02789.
Sanh, Victor, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, et al. 2022. “Multitask Prompted Training Enables Zero-Shot Task Generalization.”https://arxiv.org/abs/2110.08207.
Taori, Rohan, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. “Stanford Alpaca: An Instruction-Following LLaMA Model.”GitHub Repository. https://github.com/tatsu-lab/stanford_alpaca; GitHub.
Wang, Yizhong, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. “Self-Instruct: Aligning Language Model with Self Generated Instructions.”https://arxiv.org/abs/2212.10560.
Wu, Minghao, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. 2023. “LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions.”https://arxiv.org/abs/2304.14402.